ArrayList
List인터페이스를 구현하기 때문에 데이터의 저장순서가 유지되고 중복을 허용하고
순차적으로 추가/삭제 하는 경우에는 ArrayList가 LinkedList보다 빠르다
컬렉션 프레임워크에서 가장 많이 사용되는 컬렉션이다.🔥
ArrayList는 배열을 이용한 자료구조의 형태여서 데이터를 읽어오고 저장하는 데는 좋지만
데이터가 저장공간(Size가 Capacity)보다 커져서 저장공간(Capacity)를 넘게되어 용량을 변경해야 할 때는
새로운 배열을 생성 한 후 기존의 배열로 부터 데이터를 복사해야 하기 때문에 효율이 떨어지기 때문에
처음 인스턴스를 생성 할 때 저장 개수를 잘 고려해 충분한 용량의 인스턴스를 생성하는게 좋다.
Size가 Capacity보다 커져서 Capacity가 늘어 나는 과정의 효율이 떨어짐생성자
List<E> arrayList = new ArrayList<E>();메소드
| 메서드 | 설명 | 예제 |
| Object get(in index) | 지정된 위치(index)에 저장된 객체를 반환한다. | ⭐ |
| List subList(int fromIndex, int toIndex) | fromIndex부터 toIndex사이에 저장된 객체를 반환한다. | ⭐ |
| boolean add(Object obj) | ArrayList의 마지막에 객체를 추가한다. 추가에 성공하면 true를 반환 | ⭐ |
| void add(int index, Object element) | 지정된 위치(index)에 객체를 저장한다. 자리에 있던 기존의 데이터는 뒤로 밀려나기만 할 뿐 삭제되지 않는다. ex) add(2, Object) → 기존, 기존, 추가, 기존, 기존 |
|
| void addAll(Collection c) | 주어진 컬렉션의 모든 객체를 저장한다.(마지막 index의 뒤로 붙임) ex) addAll(Collection) → 기존, 기존, 기존, 기존, 추가, 추가, ... |
⭐ |
| void addAll(int index, Collection c) | 지정한 위치부터 주어진 컬렉션의 데이터를 저장한다. 자리에 있던 기존의 데이터는 뒤로 밀려나기만 할 뿐 삭제되지 않는다. ex) addAll(2, Collection) → 기존, 기존, 추가, 추가, ... , 기존, 기존 |
|
| Object set(int index, Object obj) | 주어진 객체(obj)를 지정한 위치(index)에 저장한다.자리에 있던 기존의 데이터는 삭제되고 새로운 데이터가 대체되어 들어간다.ex) set(2, Object) → 기존, 기존, 대체, 기존, 기존 | ⭐ |
| Object clone() | ArrayList를 복제한다. | ⭐ |
| Object remove(int index) | 지정된 위치(index)에 있는 객체를 제거한다. | ⭐ |
| boolean remove(Object obj) | 지정된 객체를 제거한다.(성공하면 true) | |
| boolean removeAll(Collection c) | 지정한 컬렉션에 저장된 것과 동일한 객체들을 ArrayList에서 제거한다. | |
| boolean retainAll(Collection c) | ArrayList에 저장된 객체 중에서 주어진 컬렉션과 공통된 것들만 남기고 제거한다. | ⭐ |
| void clear() | ArrayList를 완전히 비운다. | ⭐ |
| int size() | ArrayList에 저장된 객체의 개수를 반환한다. | ⭐ |
| boolean isEmpty() | ArrayList가 비어있는지 확인한다. | ⭐ |
| void sort(Comparator c) | 지정된 정렬기준(c)으로 ArrayList를 정렬한다. | ⭐ |
| boolean contains(Object obj) | 지정된 객체(obj)가 ArrayList에 포함되어 있는지 확인한다. | ⭐ |
| int indexOf(Object obj) | 지정된 객체(obj)가 저장된 위치를 찾아 반환한다. | ⭐ |
| int lastIndexOf(Object obj) | 지정된 객체(obj)가 저장된 위치를 뒤에서 부터 역방향으로 찾아 반환한다. | ⭐ |
| Iterator iterator() | ArrayList의 Iterator객체를 반환한다. | ⭐ |
| ListIterator listIterator() | ArrayList의 ListIterator를 반환한다. | ⭐ |
| ListIterator listIterator(int index) | ArrayList의 지정된 위치부터 시작하는 ListIterator를 반환한다. | |
| void ensureCapacity(int minCapacity) | ArrayList의 용량이 최소한 minCapacity가 되도록 한다. | ⭐ |
| void trimToSize() | 용량의 크기에 맞게 줄인다.(빈 공간을 없앤다.) | ⭐ |
| Object[] toArray() | ArrayList에 저장된 모든 객체들을 객체배열로 반환한다. | ⭐ |
| Object[] toArray(Obejct[] objArr) | ArrayList에 저장된 모든 객체들을 객체배열 objArr에 담아 반환한다. |
LinkedList
List를 구현한 컬렉션 이기 때문에 데이터의 저장순서가 유지되고 중복을 허용한다
중간 데이터를 추가/삭제 하는 경우에는 LinkedList가 ArrayList보다 빠르다🌠
생성자
//제너릭 타입 객체만 사용 가능
LinkedList<E> linkedList = new LinkedList<E>();
//Object 타입으로 선언됨
LinkedList linkedList = new LinkedList();메소드
| 메서드 | 설명 | 예제 |
| Object get(in index) | 지정된 위치(index)에 저장된 객체를 반환한다. | ⭐ |
| List subList(int fromIndex, int toIndex) | fromIndex부터 toIndex사이에 저장된 객체를 List로 반환한다. | ⭐ |
| boolean add(Object obj) | LinkedList의 마지막에 객체를 추가한다. 추가에 성공하면 true를 반환 | ⭐ |
| void add(int index, Object element) | 지정된 위치(index)에 객체를 저장한다. 자리에 있던 기존의 데이터는 뒤로 밀려나기만 할 뿐 삭제되지 않는다. ex) add(2, Object) → 기존, 기존, 추가, 기존, 기존 |
|
| void addAll(Collection c) | 주어진 컬렉션의 모든 객체를 저장한다.(마지막 index의 뒤로 붙임) ex) addAll(Collection) → 기존, 기존, 기존, 기존, 추가, 추가, ... |
⭐ |
| void addAll(int index, Collection c) | 지정한 위치부터 주어진 컬렉션의 데이터를 저장한다. 자리에 있던 기존의 데이터는 뒤로 밀려나기만 할 뿐 삭제되지 않는다. ex) addAll(2, Collection) → 기존, 기존, 추가, 추가, ... , 기존, 기존 |
|
| Object set(int index, Object obj) | 지정한 위치(index)의 객체를 주어진 객체(obj)로 바꾼다.자리에 있던 기존의 데이터는 삭제되고 새로운 데이터가 대체되어 들어간다.ex) set(2, Object) → 기존, 기존, 변경, 기존, 기존 | ⭐ |
| Object remove(int index) | 지정된 위치(index)에 있는 객체를 제거한다. | ⭐ |
| boolean remove(Object obj) | 지정된 객체를 제거한다.(성공하면 true) | |
| boolean removeAll(Collection c) | 지정한 컬렉션에 저장된 것과 동일한 노드들을 LinkedList에서 제거한다. | |
| boolean retainAll(Collection c) | LinkedList에 저장된 객체 중에서 주어진 컬렉션과 공통된 것들만 남기고 제거한다. | ⭐ |
| void clear() | LinkedList를 완전히 비운다. | ⭐ |
| int size() | LinkedList에 저장된 객체의 개수를 반환한다. | ⭐ |
| boolean isEmpty() | LinkedList가 비어있는지 확인한다. | ⭐ |
| boolean contains(Object obj) | 지정된 객체(obj)가 LinkedList에 포함되어 있는지 확인한다. | ⭐ |
| boolean containsAll(Collection c) | 지정된 컬렉션의 모든 요소가 포함되었는지 알려줌. | |
| int indexOf(Object obj) | 지정된 객체(obj)가 저장된 위치를 찾아 반환한다. | ⭐ |
| int lastIndexOf(Object obj) | 지정된 객체(obj)가 저장된 위치를 뒤에서 부터 역방향으로 찾아 반환한다. | ⭐ |
| Iterator iterator() | LinkedList의 Iterator객체를 반환한다. | ⭐ |
| ListIterator listIterator() | LinkedList의 ListIterator를 반환한다. | ⭐ |
| ListIterator listIterator(int index) | LinkedList의 지정된 위치부터 시작하는 ListIterator를 반환한다. | |
| Object[] toArray() | LinkedList에 저장된 모든 객체들을 객체배열로 반환한다. | ⭐ |
| Object[] toArray(Obejct[] objArr) | LinkedList에 저장된 모든 객체들을 객체배열 objArr에 담아 반환한다. | |
| Object element() | LinkedList에 첫 번째 노드를 반환 | |
| boolean offer(Obejct obj) | 지정된 객체(obj)를 LinkedList의 끝에 추가. 성공하면 true 실패하면 false |
|
| Object peek() | LinkedList의 첫 번째 요소를 반환 | |
| Object poll() | LinkedList의 첫 번째 요소를 반환LInkedList의 요소에서는 제거된다. | |
| Object remove() | LinkedList의 첫 번째 요소를 제거 | |
| void addFirst(Object obj) | LinkedList의 맨 앞에 객체(obj)를 추가 | |
| void addLast(Objec obj) | LinkedList의 맨 뒤에 객체(obj)를 추가 | |
| void push(Object obj) | 맨 앞에 객체(obj)를 추가 (addFirst와 동일) | |
| Iterator descendingItorator() | 역순으로 조회하기 위한 DescendingItorator를 반환 | |
| Object getFrist() | LinkedList의 첫번째 노드를 반환 | |
| Object getLast() | LinkedList의 마지막 노드를 반환 | |
| boolean offerFirst(Object obj) | 지정된 객체(obj)를 LinkedList의 맨 앞에 추가, 성공하면 ture | |
| boolean offerLast(Object obj) | 지정된 객체(obj)를 LinkedList의 맨 뒤에 추가, 성공하면 ture | |
| Object peakFirst() | 첫번째 노드를 반환 | |
| Object peakLast() | 마지막 노드를 반환 | |
| Object pollFirst() | 첫번째 노드를 반환하면서 제거 | |
| Object pollLast() | 마지막 노드를 반환하면서 제거 | |
| Obejct removeFirst() | 첫번째 노드를 제거 | |
| Object removeLast() | 마지막 노드를 제거 | |
| Object pop() | 첫번째 노드를 제거 (removeFirst와 동일) | |
| boolean removeFirstOccurrence( Obejct obj) |
첫번째로 일치하는 객체를 제거 | |
| boolean removeLastOccurrence( Obejct obj) |
마지막으로 일치하는 객체를 제거 | |
HashSet
데이터의 저장순서가 유지되지 않고 중복을 허용하지 않는다.특징을 히용하여 컬렉션 내의 중복 요소를 제거하기 편하다.해싱(Hashing)을 사용하여많은 양의 데이터를 검색하는데 높은 성능을 보인다.**
Set인터페이스를 구현한 가장 **대표적인 컬렉션이다.👏
**💡(많은 양의 데이터를 저장하는데 적합하다.)**
HashSet은 저장순서를 유지하지 않기 때문에 만약 저장순서를 유지하고 싶다면 LinkedHashSet을 사용해야 한다.
생성자
Set<K> set = new HashSet<K>();메소드
add, addAll - 객체 추가
| 메소드 | 설 명 |
| boolean add(Object obj) | 새로운 객체를 저장한다. |
| boolean addAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체들을 추가한다.(합집합) |
clear - 모든 데이터 삭제
| 메소드 | 설 명 |
| void clear() | 저장된 모든 객체를 삭제한다. |
clone - 복제
| 메소드 | 설 명 |
| Object clone() | HashSet을 복사해서 반환한다.(얕은 복사) |
contains, containsAll - 데이터 확인
| 메소드 | 설 명 |
| boolean contains(Object obj) | 지정된 객체를 포함하고 있는지 알려준다. |
| boolean containsAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체들을 포함하고 있는지 알려준다. |
isEmpty() - 비었는지 확인
| 메소드 | 설 명 |
| boolean isEmpty() | HashSet이 비었는지 알려준다. |
iterator() - Iterator반환
| 메소드 | 설 명 |
| Iterator iterator() | Iterator를 반환한다. |
remove, removeAll - 삭제
| 메소드 | 설 명 |
| boolean remove(Object obj) | 지정된 객체를 HashSet에서 삭제한다. (성공하면 true, 실패하면 false를 반환한다.) |
| boolean removeAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체와 동일한 것들을 HashSet에서 삭제한다.(차집합)(성공하면 true, 실패하면 false를 반환한다.) |
retainAll - 동일한 것만 남기고 삭제
| 메소드 | 설 명 |
| boolean retainAll(Collection c) | 주어진 컬렉션에 저장된 객체와 동일한 것만 남기고 삭제한다. (교집합) |
size() - 저장 개수 반환
| 메소드 | 설 명 |
| int size() | 저장된 객체의 개수를 반환한다. |
toArray() - 배열화
| 메소드 | 설 명 |
| Object[] toArray() | 저장된 객체들을 객체배열의 형태로 반환한다. |
| Object[] toArray(Object[] arr) | 저장된 객체들을 주어진 객체배열(arr)에 담는다. |
HashMap
키(key)와 값(value)을 묶어 하나의 데이터로 저장한다
해싱(Hashing)을 사용하여 많은 양의 데이터를 검색하는데 높은 성능을 보인다.
💡(많은 양의 데이터를 저장하는데 적합하다.)
HashMap은 키와 값이 각각 Object타입으로 어떠한 객체도 저장할 수 있지만
키는 주로 String을 대문자 또는로 통일해서 사용하곤 한다.
| 키(key) 컬렉션 내의 저장된 값을 찾는데 사용되기 때문에 유일해야 한다. 값(value) 키(key)와 달리 데이터의 중복을 허용한다. |
생성자
Map<K, V> hashMap = new HashMap<K, V>();메소드
| 메소드 | 설명 |
| Object get(Object key) | 지정된 키(key)의 값(객체)을 반환, 못찾으면 null 반환 |
| Object getOrDefault(Object key, Object defaultValue) | 지정된 키(key)의 값(객체)을 반환 못찾으면 기본값(defaultValue)에 지정된 객체를 반환. |
| Object put(Object key, Object value) | 지정된 키와 값을 HashMap에 저장 |
| void putAll(Map m) | Map에 저장된 모든 요소를 HashMap에 저장 |
| Object clone() | 현재 HashMap을 복제해서 반환 |
| Object remove(Object key) | HashMap에서 지정된 키로 저장된 값(객체를 제거) |
| Object replace(Object key, Object value) | 지정된 키의 값을 지정된 객체(value)로 대체 |
| boolean replace(Object key,Object oldValue, Object newValue) | 지정된 키와 객체(oldValue)가 모두 일치하는 경우에만새로운 객체(newValue)로 대체 |
| void clear() | HashMap에 저장된 모든 객체를 제거 |
| int size() | HashMap에 저장된 요소의 개수를 반환 |
| boolean isEmpty() | HashMap이 비어있는지 알려준다. |
| boolean containsKey(Object key) | HashMap에 지정된 키(key)가 포함되어있는지 알려준다 포함되어 있으면 ture |
| boolean containsValue(Object value) | HashMap에 지정된 값(value)가 포함되어있는지 알려준다 포함되어 있으면 true |
| Set keySet() | HashMap에 저장된 모든 키가 저장된 Set을 반환 |
| Set entrySet() | HashMap에 저장된 키와 값을 엔트리(키와 값의 결합)의형태로 Set에 저장해서 반환 |
| Collection values() | HashMap에 저장된 모든 값을 컬렉션의 형태로 반환 |
HashMap
HashMap과 구조가 비슷하지만 용도는 다름
HashTable은 키와 값을 1:1형태로 가져가며 HashTable에 저장이 됨
-> 키는 값을 식별하기 위한 고유한 키, 값은 키가 가진 값을 의미함
HashMap과 반대로 동기화가 이루어짐
HashMap에서는 값으로 null이 입력이 가능하지만 HashTable에서는 null 입력이 불가능
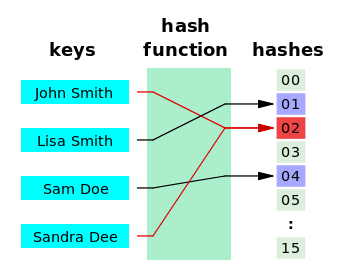
위와 같이 키, 값 형태를 가짐
키는 중복이 안 되지만 값은 중복을 허용
HashTable 생성자
Map<K, V> hashMap = new HashMap<K, V>();Map<K, V> hashTable = new HashTable<K, V>();
메소드
| void clear() | 해당 맵(map)의 모든 매핑(mapping)을 제거함. |
| boolean containsKey(Object key) | 해당 맵이 전달된 키를 포함하고 있는지를 확인함. |
| boolean containsValue(Object value) | 해당 맵이 전달된 값에 해당하는 하나 이상의 키를 포함하고 있는지를 확인함. |
| V get(Object key) | 해당 맵에서 전달된 키에 대응하는 값을 반환함. 만약 해당 맵이 전달된 키를 포함한 매핑을 포함하고 있지 않으면 null을 반환함. |
| boolean isEmpty() | 해당 맵이 비어있는지를 확인함. |
| Set<K> keySet() | 해당 맵에 포함되어 있는 모든 키로 만들어진 Set 객체를 반환함. |
| V put(K key, V value) | 해당 맵에 전달된 키에 대응하는 값으로 특정 값을 매핑함. |
| V remove(Object key) | 해당 맵에서 전달된 키에 대응하는 매핑을 제거함. |
| boolean remove(Object key, Object value) | 해당 맵에서 특정 값에 대응하는 특정 키의 매핑을 제거함. |
| V replace(K key, V value) | 해당 맵에서 전달된 키에 대응하는 값을 특정 값으로 대체함. |
| boolean replace(K key, V oldValue, V newValue) | 해당 맵에서 특정 값에 대응하는 전달된 키의 값을 새로운 값으로 대체함. |
| int size() | 해당 맵의 매핑의 총 개수를 반환함. |
'자바~하둡' 카테고리의 다른 글
| JavaScript (0) | 2021.12.27 |
|---|---|
| 자바정리 ver.0.2 (0) | 2021.12.26 |
| JSP(CSS)_2 (0) | 2021.12.24 |
| JSP(CSS) (0) | 2021.12.23 |
| M.V.C. C.R.U.D. (0) | 2021.12.22 |